요즘은 PS나 CP보다 인공지능 다룰 일이 더 많다. 지나가는 생각들이 잊혀지는 게 싫어서 카테고리를 만들었다.
인공지능
만들어진 지능이다. 이 단어가 간편한 대신 막연한 두려움을 주는 이상한 단어인데, 기술적으로는 "통계적 추론의 자동화" 가 더 맞는 단어인 것 같다. 인공지능의 발전은 최근의 문제가 아니다. 이미 Neural network와 perceptron에 대한 개념은 1970년대부터 논의된 내용이고, GPU와 프로그래밍 툴, 시장의 형성으로 최근 들어 주목받았을 뿐이다.
학습?
학습 = 행렬뺄셈
인공지능을 잘하고 싶다면 이것만 외워도 반은 먹고 들어가는 것 같은데
Weight 초기화 → 모의예측 → Loss 계산 → Loss가 낮아지는 방향으로 weight 업데이트
인공지능의 기본 작동 원리는 이 네 가지고, 이걸 인공지능의 "학습" 이라고 한다. "학습"이 무엇인지 모르고 인공지능을 말하는 수없이 많은 사람들을 보다보면 제발 수능 국어 지문에 매년 이 내용이 나오길 바랄 뿐이다.
하나씩 더 설명하자면,
- Weight는 행렬이다. 가중치라고도 하는데 개인적으로 가중치와 같은 문과적 용어가 아닌 Weight matrix 를 선호한다. 기호는 W많이 씀.
- W의 초기화는 보통 random으로 한다. 다르게 하면 효율이 좋다는데 나같은 응애 개발자에겐 상관 없음.
- Loss는 무엇이냐? 하면 어려우니 나중에
- 업데이트란 무엇이냐, 하면 행렬 뺄셈이다. Weight matrix를 업데이트 하여 내가 원하는 예측을 하도록 아주 약간 이동시키는 것이다. 이 또한 문과적 용어들 투성이 이므로 뺄셈으로 설명할 것이다.
아주 약간 업데이트
말을 쪼개보자. "아주 약간"과 "업데이트"가 있다. 먼저 업데이트란, 나같이 유튜브 프리미엄 안 쓰는 사람들을 위한 "라스트워" 를 생각하면 쉽다. 왼쪽과 오른쪽의 갈림길이 있다. 왼쪽으로 가면 피가 1깎인다. 오른쪽으로 가면 피가 2 오른다. 당연히 오른쪽을 가야 한다.

이걸 하나의 선분 그래프라고 생각해보자. 내가 있는 점의 왼쪽은 나보다 낮고, 오른쪽은 나보다 높다. 나는 낮은 곳에 있을 수록 이득이다. 그러면 당연히 왼쪽으로 가야 한다.

그렇다면 수학적으로 이걸 어떻게 판단할 것이냐? 할 때 미분을 쓴다. 이래서 고2때 도함수의 정의를 잘 배워야 하는 것이다. 미분을 해서 함수가 증가함수라면 왼쪽으로, 감소함수라면 오른쪽으로 이동한다. 그래서 기울기 × -1 을 해준다. 행렬의 뺄셈인 이유. 기울기를 구할 때는 고딩때 배운 dy/dx가 아닌 편미분이라는 걸 이용한다.
사실 dy/dx도 편미분이긴 하고 정의를 잘 생각하면 쉽다. y의 x에 대한 변화량, x가 1 변할 때 y는 얼마나 변하냐? 하는 건데 나머지도 비슷하다. 철수의 키, 몸무게로 여자친구 유무를 예측해보자. 키가 클수록 몸무게가 적을수록 여자친구가 있을 확률이 높다면 키와 몸무게 각각에 대해 여자친구 존재 확률이 변하는 정도를 파악해야 하는 것이다. 아주 쉽게 여기까지만 이해하자.
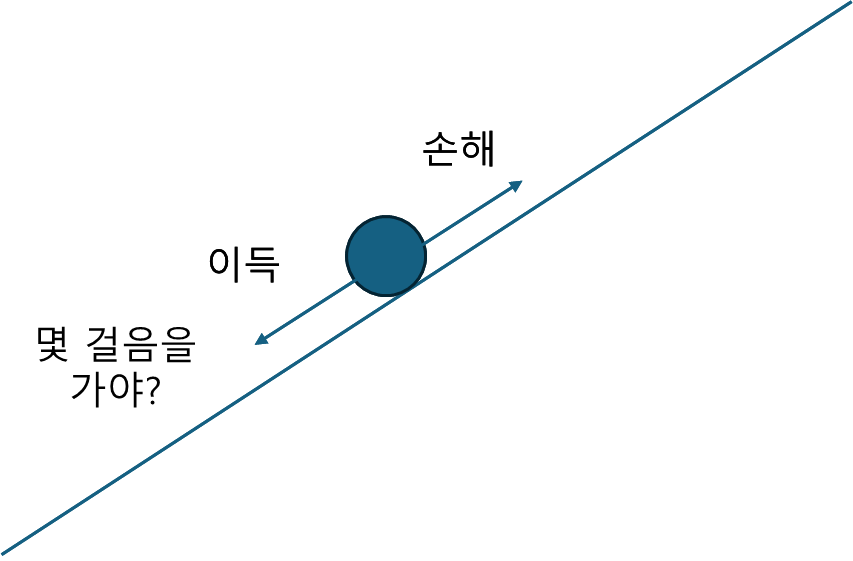
"아주 약간"이란 Learning rate를 말한다. 앞서 갈림길 얘기를 했는데 사실 모델학습은 갈림길과 같이 단순한 결정이 아닌 몇걸음을 걸어갈것이냐? 의 문제를 매번 해결해야 한다. 만약 원하는 예측을 위해 4걸음을 걸어갔다가 엉뚱한 동네로 넘어가거나 웅덩이에 빠져버리면 안된다. 그래서 걸음수를 최소화하는 것이 필요하고, (정해진 방향) × (작은 값)으로 변화를 최소화한다. 이때의 작은 값이 Learning rate이다. 말 그대로 학습을 얼마나 할 것이냐, 즉 학습 속도에 대한 문제. 너무 느려도 안되므로 Learning rate를 적절히 하는 것이 중요하다.
그래서 정리하면 학습은 $W-LR\times \triangledown \dfrac{Loss(X)}{X}$ 의 반복이다. 뭔소린가 싶을텐데 LR = Learning rate, 삼각형 뒤집힌건 편미분 기호다.
예측?
예측 = 행렬곱
여기까지 왔다면 학습 이라는게 "전문과"들이 말하는 문과적 용어가 아닌 단순히 사칙연산의 상위호환임을 알 수 있다. 그렇다면 학습보다도 더 문과적인 용어 "예측" 이란 무엇이냐? 하면 이렇다.
인공지능 예측이 1초 내로 이루어지고 ChatGPT가 수 초 안에 대답할 수 있는 이유는 서비스에서 학습된 모델을 내놓기 때문이다. 인공지능에 컴퓨터 성능이 좋아야 한다거나, 첨단 시장이라거나 하는 건 대부분 학습의 얘기다. 한 번 가르치는게 어렵지 써먹는 건 쉽다는 말이다.
예측은 수많은 머신러닝 방법론에 따라 다른데, 내가 아는 한에서 가장 기초적인 건 $W \sdot X$, 행렬곱 이다. 왜냐? 내가 모델을 그렇게 설계했기 때문이다. 다른 방법을 써도 되지만 수만개의 데이터를 수십만번 학습시키는 상황에서 곱셈보다 더 단순하고 효율적인 방법은 잘 없다.
이게 뭔소린가 하니, 학습은 모의예측과 Loss 계산, Loss가 낮아지는 방향으로 업데이트를 하는 것이라고 했다. 모의예측은 예측과 같은 방법을 쓴다는 건데 learning rate를 이용해 원하는 방향으로 가는 보폭을 줄여놨다. 그래서 수천 수만번은 걸어야 원하는 위치에 정확히 들어간다. 그럼 모의예측도 수만번을 한다는 건데 이때 어려운 방법을 쓰고 하면 굳이? 싶은 거다. 어차피 빠르고 정확하게 하는 건 행렬곱으로도 충분하고, 내가 아는 것도 여기까지 뿐이니 행렬곱만 얘기해보자.
예를 들어보자. 롤 실력(Y) 을 0부터 100까지 점수로 매길 때 피시방에 있는 시간(P) 과 공부 시간 (S) 을 입력으로 롤점수를 예측해보자. 인공지능 학습 결과 $Y = (P \times 120 - S \times 10) / 24$ 라고 나왔다면
$Y = [P, S] \sdot [120/24, -10/24]$ 으로 생각할 수 있다. 행렬곱 안맞는데요? 하면 그냥 넘어가자. 여기서 P, S가 입력, 120/24, -10/24가 Weight가 된다. 이 곱셈을 하는데는 2번의 연산만 하면 된다. 행렬곱에서 이전에 Freivald's algorithm 이나 앞으로 얘기할 FFT등의 복잡한 내용을 쓸 필요도 없이 m×p×q 번의 연산을 하면 되고 대부분의 알고리즘에서 이 값이 매우 작다.
On device

그럼 LG에서 gram pro를 통해 NPU를 달겠다고 하고 갤럭시도 이런 얘기를 하는데 이건 왜 그런거냐? 하면 기기 내부에서 예측이 아닌 "학습"을 하려는 것이다. 데이터를 수집해서 실시간 모델 학습을 진행하겠다는 것인데 기존의 방법은 데이터를 수집한 뒤 데이터 센터로 사용자 데이터를 보내서 학습을 돌린 뒤 Weight를 기기로 다시 보내주는 구조라면, 왜인지는 모르겠으나 그 과정을 더 빠르게 기기단에서 해주겠다는 얘기인 것 같다. 쉽게 말하면
기존 : 기기 → 데이터센터 → 분석 → 모델전송 → 기기에서 활용
- 장점 : 데이터 통합 분석, 저렴하고 가벼운 기기
- 단점 : 데이터 수집량 제한, 서버 부담, 인터넷 접속 필요 등등
온디바이스 : 기기 → 기기에서 분석 → 바로 활용
- 장점 : 모든 데이터의 수집과 분석 가능, 서버 부담 줄어듦, 오프라인 학습 가능
- 단점 : 비싼 가격 (장점일지도) 말고 없음?
을 하려는 것 같다. 사실 NPU칩 하나 추가한다고 무게가 크게 차이나지도 않고, 아마 하드웨어 업체가 AI시장에서 점유율을 높이기 위한 작업인 것 같은데 사용자에게 어떻게 도움이 될지는 모르겠다. 배터리 소모가 줄어들고, 갤러리에서 내 얼굴 잘 찾아주는 정도? 아무튼 예측 또한 사칙연산의 상위호환일 뿐이고 인공지능의 핵심은 학습이다.
오늘은 인공지능의 학습과 예측에 대해 알아보았다. 인공지능이 진짜 "지능" 이 아닌 그저 사칙연산을 기반으로 한 학습과 예측에 의한 반복된 통계적 추론에 불과하다는 것을 잘 안다면 "인공지능이 세상을 지배한다"는 생각은 할 수가 없을 것이다.
오랜만에 글을 쓰려니 분량조절이 안돼서 다음 글에서 최적화 내용인 Loss, Gradient descent, Momentum 하고 "나 인공지능 해요" 하는 사람들의 대표적인 실수 몇 가지를 다루어보려고 한다. 추가로 Linear / Logistic regression, CNN, RNN, LSTM 을 모듈 없이 구현해 보는 방법도 천천히 다루어보자.
'인공지능' 카테고리의 다른 글
| 02. Deepseek 쇼크, 말이 안되는 3가지 이유 (2) | 2025.02.05 |
|---|
댓글